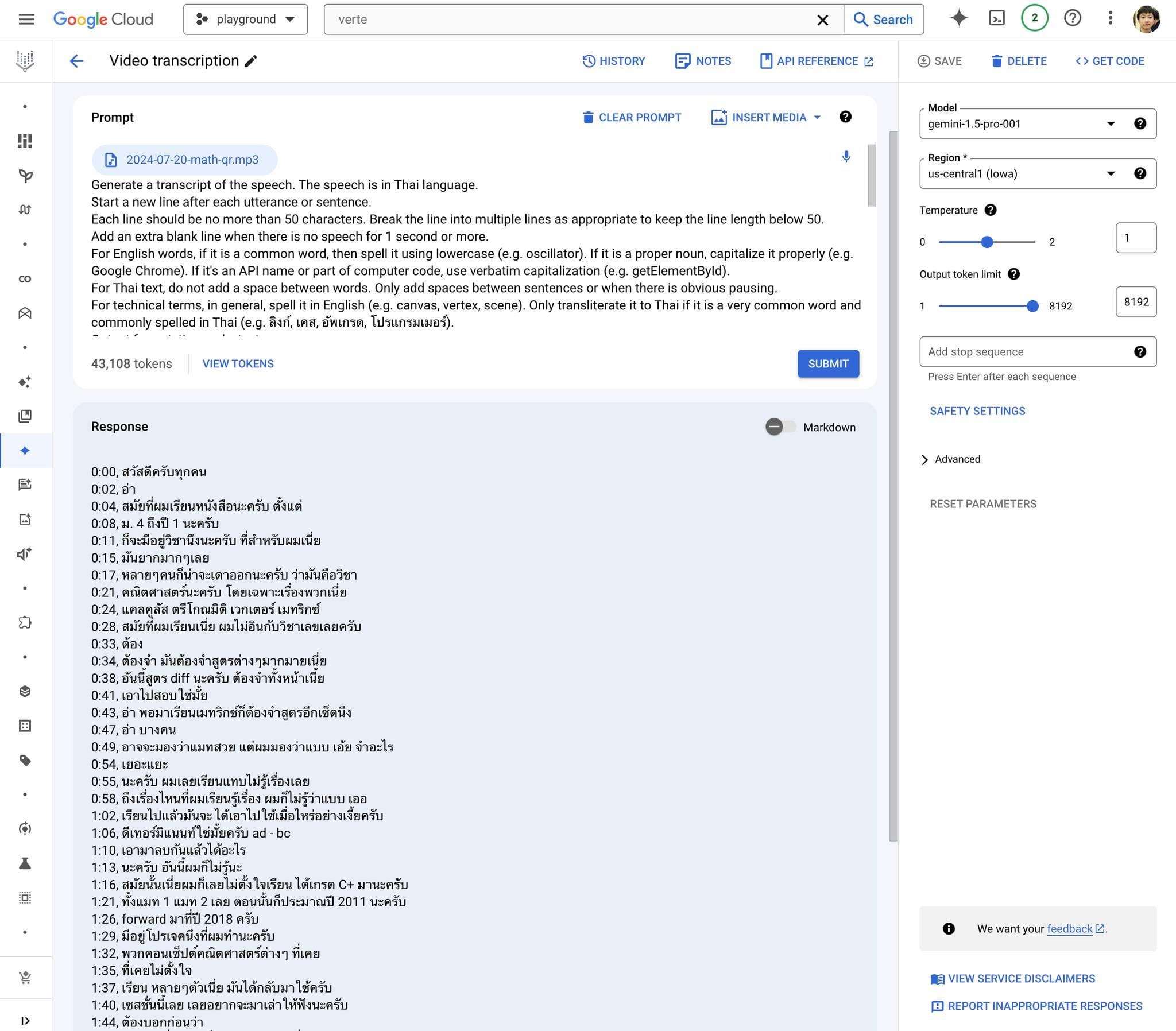
ในที่สุดก็เจอ speech-to-text model ที่ใช้กับ tech talk ภาษาไทยได้จริงๆ ซะที~
ปกติพวกเครื่องมือ automated speech recognition ที่ถอดคำพูดภาษาไทยได้ มักจะ (1) ไม่สามารถสะกดคำภาษาอื่นได้เลย เวลาเจอคำภาษาอังกฤษ บางทีมันจะข้ามไปเลย (2) ถึงบางตัวจะสะกดได้ ก็ยังมั่วมากๆ เพราะไม่ค่อยรู้จักศัพท์เทคนิค
ก่อนหน้านี้ตัวที่ดูมีแววมากที่สุดคือ Whisper ของ OpenAI และ Whisper Zero ของ Gladia (ที่เอา Whisper มาพัฒนาเพิ่มเติม) แต่ก็ยังต้องแก้ค่อนข้างเยอะอยู่ดี
แต่ล่าสุดพบว่า เราส่งไฟล์ mp3 ให้โมเดล “Gemini 1.5 Pro” ของ Google ช่วยถอดคำพูดให้ได้เลย ด้วยความที่มัน multimodal มันเลยรู้ทั้งภาษาไทย ภาษาอังกฤษ และศัพท์เทคนิคต่างๆ มันก็สะกดได้อย่างถูกต้องเกือบหมด ต้องแก้เองน้อยมากๆ
โดยเฉพาะถ้าเราใส่ prompt ให้ด้วย ว่าหัวข้อพูดเรื่องอะไร บรรยายโดยใคร จากบริษัทไหน และใส่ abstract ของ talk คร่าวๆ มันจะสะกดคำต่างๆ ได้แม่นยำขึ้นมาก
ใช้งานโมเดลนี้ ไม่ต้องเขียนโค้ดเลย ไปเล่นที่ Vertex AI ใน Google Cloud Console ได้เลย
ราคาเท่าไหร่? — แบ่งเป็นค่า input และค่า output
input:
・ ไฟล์นี้ ยาว ~24 นาที
・ คิดเป็นประมาณ ~43,000 token
・ คำนวณเป็นเงินคือ ~6 บาท
output:
・ ประมาณ ~10,000 token
・ คำนวณเป็นเงินคือ ~4 บาท
โดยรวมก็คือราคาประมาณ 10 บาท
ส่วนข้อเสียที่เจอ คือ
・ timecode ที่ output ออกมา (ตรงด้านซ้าย) มันมั่วหมดเลย แปลว่าต้องเอาไป sync กับวีดีโอเองอีกที
・ โมเดลสามารถ output ได้ทีละ 8192 token และเวลาอัพโหลดไฟล์ มันจำกัดขนาดที่ 7 MB แปลว่าต้องแบ่ง talk เป็นหลายๆ part แล้วถอดคำพูดทีละส่วน